
 Pandas介绍
Pandas介绍
# 介绍
pandas是python的一个强大的数据分析工具
在线的ipython编辑器 (opens new window)
# 创建文件
创建文件可以直接使用pd对象的to_excel函数即可
data = [
{"id":1 , "username":'张三'},
{"id":2 , "username":'李四'}
]
df = pd.DataFrame(data)
# 设置索引,第一列,默认情况下会生成一个索引列(序号),set_index会返回一个DataFrame,所以这里需要df重新赋值
df = df.set_index("id")
df.to_excel("/Users/fangzheng/Downloads/pandas_excel.xlsx")
print("Done!")
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
保存后的结果如下所示:
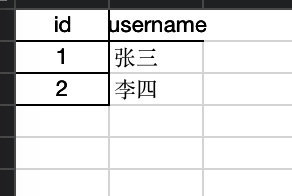
其中,df中有很多保存为文件的函数(如下)
# 读取文件
读取文件可以使用pd的read开头函数
excel = pd.read_excel("/Users/fangzheng/Downloads/pandas_excel.xlsx")
print(excel.shape) # 获取(行数,列数)
print(excel.columns) # 获取所有列名
print(excel.head(1)) # 获取第一行
print(excel.head())
1
2
3
4
5
2
3
4
5
控制台打印结果:
/usr/local/bin/python3.7 /Users/fangzheng/PycharmProjects/pydemo/数据分析/pandas/create_excel.py
(2, 2)
Index(['id', 'username'], dtype='object')
id username
0 1 张三
id username
0 1 张三
1 2 李四
Process finished with exit code 0
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 读取指定位置数据的Excel
例如:如下Excel内容,数据不是从第一行第一列开始的,那读取的时候就需要指定读取的行和列坐标了
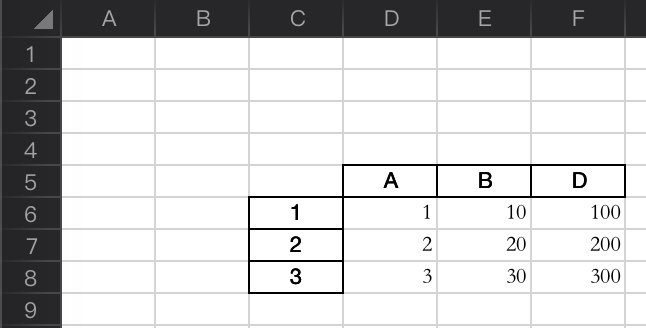
代码如下:
# 读取指定行列的Excel,有些时候Excel里的数据不是在首行首列,那就需要指定读取的起始行和列
# skiprows:表示跳过几行,从第几行开始读
# usecols:表示读取的列,从C到F
df = pd.read_excel(file,skiprows=4,usecols='C:F')
print(df)
1
2
3
4
5
2
3
4
5
# 行、列、单元格
在pandas中,不管是行还是列,都可以用作series来表示,当把一个series加入一个dataframe里时可以指定是以行的方式插入还是以列的方式插入。所以,series既可以是行也可以是列。
# 创建Series
# 1、创建series方式1
d = {'x':100,'y':100,'z':300} # d是一个python里的dict类型
s1 = pd.Series(d) # 当把一个python的dict类型传递给series时,dict的key就是series的x,dict的value就是serise的y
print(s1)
# 2、创建series方式2
l1 = [100,200,300]
l2 = ['x','y','z']
s2 = pd.Series(l1,index=l2)
print(s2)
# 3、创建series方式3:直接指定x和y的值
s3 = pd.Series([100,200,300],index=['x','y','z'])
print(s3)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
三种方式打印结果是一样的。
# 把Series的数据加入dataframe
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([10,20,30],index=[1,2,3],name='B')
s3 = pd.Series([100,200,300],index=[1,2,3],name='D')
# 以dict的方式把Series加入DataFrame中时,name为标题,index为行号
df = pd.DataFrame({s1.name:s1, s2.name:s2 , s3.name:s3})
print(df)
print('---------------------')
# 以list的方式把Series加入DataFrame中事,name为行号,index为标题
df2 = pd.DataFrame([s1,s2,s3])
print(df2)
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
结果如下
A B D
1 1 10 100
2 2 20 200
3 3 30 300
---------------------
1 2 3
A 1 2 3
B 10 20 30
D 100 200 300
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# Sheet页
# 读取多个文件,将文件内容以多个sheet的方式写入Excel中
# 读取多个文件,将文件内容以多个sheet的方式写入Excel中
# read_table:从文件、url、文件型对象中加载带分隔符的数据,默认为'\t'。(read_csv默认分隔符是逗号)
result = '/Users/fangzheng/Downloads/result.xlsx'
df1 = pd.read_table('/Users/fangzheng/Downloads/a.txt')
df2 = pd.read_table('/Users/fangzheng/Downloads/b.txt')
df3 = pd.read_table('/Users/fangzheng/Downloads/c.txt')
writer = pd.ExcelWriter(result)
df1.to_excel(writer, sheet_name='中文1')
df2.to_excel(writer, sheet_name='中文2')
df3.to_excel(writer, sheet_name='中文3')
# 必须save,要不然不会保存到本地
writer.save()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
保存结果如下:
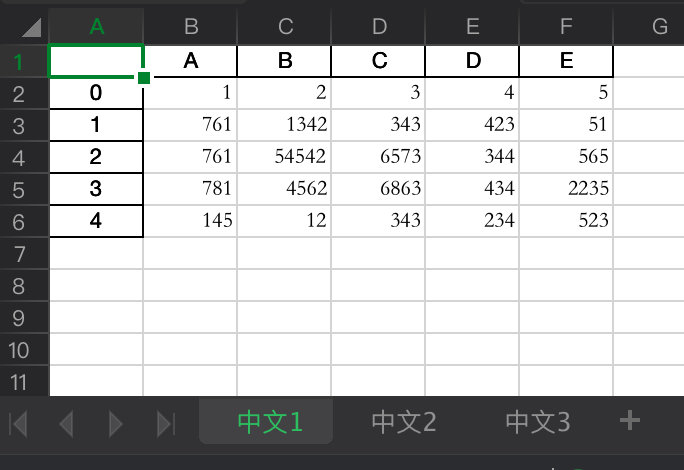
最后更新时间: 2022/7/23 10:17:11