
 数据质量管理
数据质量管理
# 什么数据质量问题?
数据质量管理(Data Quality Management):顾名思义,就是对数据的质量进行监控和治理。
数据是组织最具价值的资产之一。企业的数据质量与业务绩效之间存在着直接联系,高质量的数据可以使公司保持竞争力并在经济动荡时期立于不败之地。有了普遍深入的数据质量,企业在任何时候都可以信任满足所有需求的所有数据。
开源的数据质量管理框架:Apache Griffin官网 (opens new window)Apache Griffin入门指南 (opens new window)
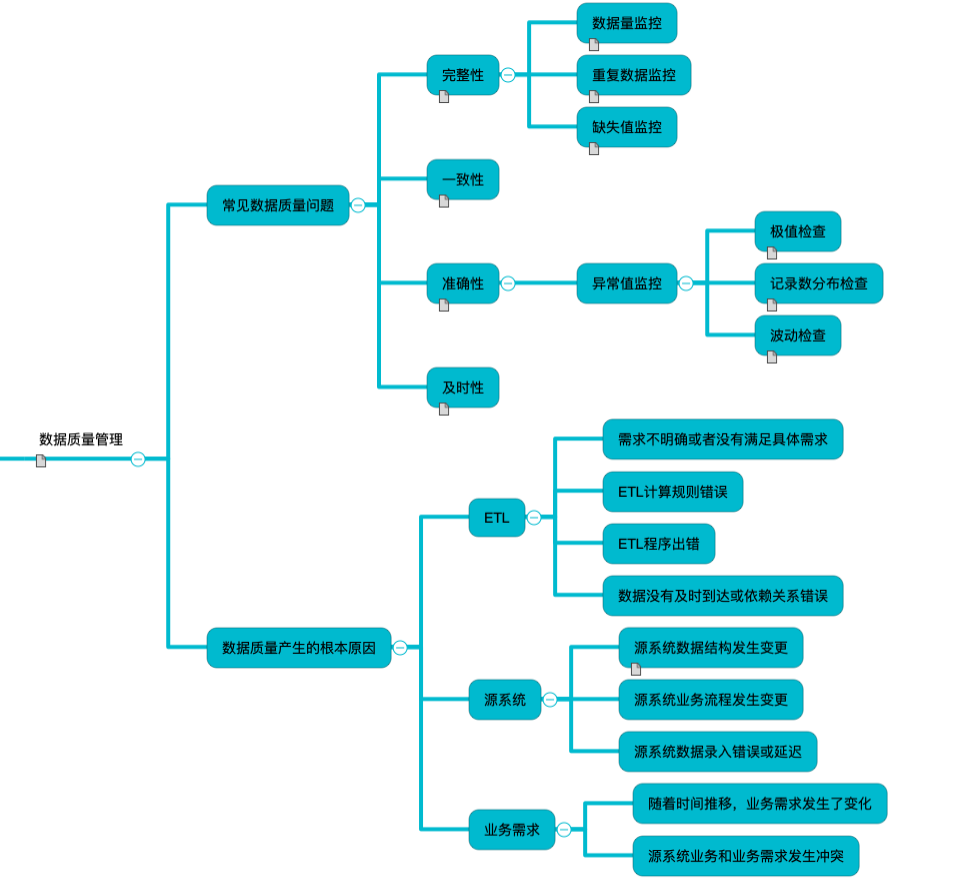
# 评估数据质量的6大标准
# 完整性 Completeness
完整性用于度量哪些数据丢失了或者哪些数据不可用。
# 规范性 Conformity
规范性用于度量哪些数据未按统一格式存储。
# 一致性 Consistency
一致性用于度量哪些数据的值在信息含义上是冲突的。
# 准确性 Accuracy
准确性用于度量 (opens new window)哪些数据和信息是不正确的,或者数据是超期的。
# 唯一性 Uniqueness
唯一性用于度量哪些数据是重复数据或者数据的哪些属性是重复的。
# 关联性 Integration
关联性用于度量哪些关联的数据缺失或者未建立索引。
# 数据质量管理的内容
数据质量的监控主要通过对数据的事前预防、事中监控、事后改善,三个方向来进行数据的全生命周期监控。

# 事前预防
事前预防,主要是针对原始数据(子龙系统)进行监控。
主要有如下几点:
- 完整性:
大多数的数据都是通过数据同步(datax、Sqoop)工具将数据从源系统同步到Hive中。我们需要监控的就是同步到Hive的数据情况。
例如:
- 监控同步数据是否有重复值
- 监控同步数据是否有缺失值
- 监控同步数据的数据量
- 一致性:
在保证了数据的完整性后,其次需要监控数据的一致性。
例如:
Hive里的数据是否和源数据一致
# 事中监控
事中监控主要是为了监控我们Hive里计算完成的数据情况。
例如:
- 调度跑批失败(由
azkaban监控) - 调度跑批成功,但是没有数据
- 调度跑批成功,有数据,但是数据计算结果不对
# 事后改善
事后改善主要是在我们监控的基础上,进行一些相应的改善工作
例如:
- 监控的异常数据,及时的推送给相应责任人、执行人
- 需要有专人专职的去负责具体的数据
# 数据质量管理的系统设计
为了更方便、灵活的对不同的数据进行不同类型的质量监控。所以需要设计一个通用的数据质量监控系统。
最初的设想:
需要监控的指标由元数据管理(配置在
MySQL中)写通用程序读取数据质量的配置信息
根据配置信息达到不同的监控类型触发不同的监控程序的效果
# 表结构设计
# 1. 数据质量字典表:
用于存储整个系统的一些常量,把这些常量用做参数用在整个系统中。
例如:常用日期(昨天日期、前天日期)
CREATE TABLE `meta_data_quality_dict` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`dict_key` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`dict_value` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`dict_type` varchar(100) CHARACTER SET latin1 DEFAULT NULL COMMENT '字典的类型:fixed固定的 ,mysql表示一条MySQL语句',
`remarks` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COMMENT='数据质量字典表';
2
3
4
5
6
7
8
# 2. 数据质量配置表:
主要用于配置相应的数据质量检查的SQL
CREATE TABLE `meta_data_quality_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`conn_id` varchar(20) CHARACTER SET latin1 DEFAULT NULL COMMENT '连接meta_connection表的ID',
`conn_type` varchar(100) CHARACTER SET latin1 DEFAULT NULL COMMENT '连接类型:默认为空(根据conn_id来查询),如果要查询hive里的数据需要配置为hive',
`title` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`check_sql` text,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
`status` int(11) NOT NULL DEFAULT '0' COMMENT '状态:1启用 0停用',
`remarks` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='数据质量配置表';
2
3
4
5
6
7
8
9
10
11
# 3. 数据质量检查表:
数据质量检查表,主要用于配置数据的质量检查的逻辑。
例如:检查类型:1两个值比较 2极值检查 3是否存在检查
CREATE TABLE `meta_data_quality_check` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`check_type` int(11) NOT NULL COMMENT '检查类型:1两个值比较 2极值检查 3是否存在检查\n',
`config_id` varchar(50) CHARACTER SET latin1 NOT NULL DEFAULT '' COMMENT '对应meta_data_quality_config表的ID字段',
`pass_condition` varchar(100) CHARACTER SET latin1 DEFAULT NULL COMMENT '检查通过的条件:例如下面的情况\n{1} >= {2}\n3>= {min_value} and 3 <= {max_value}\nexist\n',
`min_value` varchar(100) CHARACTER SET latin1 DEFAULT NULL COMMENT '最小值:只有check_type=2时,该字段才会有值',
`max_value` varchar(100) CHARACTER SET latin1 DEFAULT NULL COMMENT '最大值:只有check_type=2时,该字段才会有值',
`status` int(11) DEFAULT '0' COMMENT '状态 1启用 0停用',
`remarks` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='数据质量具体检查表';
2
3
4
5
6
7
8
9
10
11