
 Python-Flask基础
Python-Flask基础
# Flask介绍
Flask是一个非常流行的python的web框架,出生于2010年,本来这个项目只是作者在愚人节的一个玩笑,后来由于非常受欢迎,进而成为一个正式的项目。
Flask如此流行的原因:
微框架、简洁、只做它需要做的、扩展性强
Flask和相关的依赖(Jinja2,werkzeug)设计的非常优秀,用起来很爽
开发效率高,比如使用SQLAlchemy的ORM操作数据库可以节省开发者大量书写SQL的时间
社会活跃度非常高
# Flask安装
安装很简单,直接使用pip安装即可
pip install flask
# Hello Word
from flask import Flask
app = Flask(__name__)
if __name__ == '__main__':
app.run()
2
3
4
5
6
控制台打印:
* Serving Flask app "helloword" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
2
3
4
5
6
打开浏览器访问 http://127.0.0.1:5000/
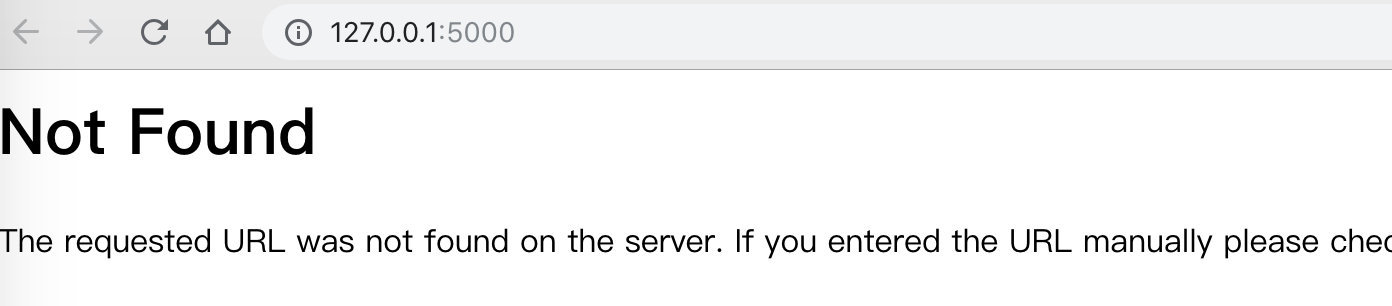
可以看到,可以访问后台,但是没找到路由。稍微改下程序,增加一个路由
from flask import Flask
app = Flask(__name__)
@app.route('/index/')
def index():
return "hello,word"
if __name__ == '__main__':
app.run()
2
3
4
5
6
7
8
9
10
打开浏览器访问 http://127.0.0.1:5000/index (opens new window)
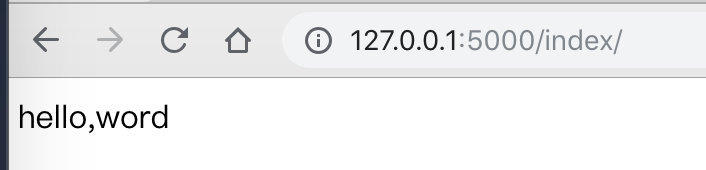
访问成功
# Debug模式
默认情况下,我们使用app.run()启动的时候,当修改Python源码的时候,是不会热加载的。所以,我们要使用Debug的模式,并且出错的时候也不会提示错误位置。
方式1:app.run(debug=True)
可以直接使用app.run(debug=True)开启debug模式
方式2:使用config.py文件
还可以使用config.py文件,以配置的方式开启debug模式
config.py文件内容
DEBUG = True
Hellowrod.py文件内容
from flask import Flask
import config
app = Flask(__name__)
# 使用配置文件的方式开启debug模式
app.config.from_object(config)
@app.route('/index/')
def index():
return "hello,word"
if __name__ == '__main__':
app.run()
2
3
4
5
6
7
8
9
10
11
12
13
控制台打印如下:
* Serving Flask app "helloword" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 944-718-490
2
3
4
5
6
7
8
9
# URL传参
@app.route('/index/<id>')
def index(id): # 这里的id需要和上面的<id>名称一样
return "你请求的参数是:{id}".format(id=id)
2
3
当请求该URL的时候
# URL反转
所谓URL反转就是通过视图(函数)名称来得到URL地址,通过Flask的url_for函数来完成。
# 1.导入url_for函数
from flask import Flask,url_for
import config
app = Flask(__name__)
app.config.from_object(config)
@app.route('/index/<id>')
def index(id): # 这里的id需要和上面的<id>名称一样
# 2. 在url_for函数中传入视图名称(函数名称)
print(url_for('user_list')) # 得到视图对应的url地址,这里是/userlist/
return "你请求的参数是:{id}".format(id=id)
@app.route('/userlist/')
def user_list():
return "this is user list page"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
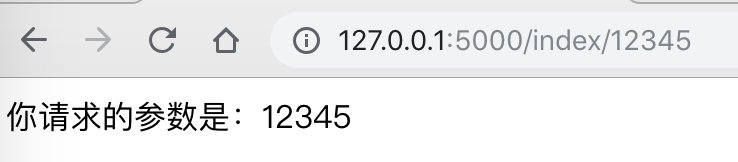
请求http://127.0.0.1:5000/index/12345 后控制台得到如下结果
/userlist/
127.0.0.1 - - [09/Dec/2018 22:35:33] "GET /index/12345 HTTP/1.1" 200 -
2
# 页面跳转
页面跳转很简单,只需要在 @app.route()注解的函数中return相应的视图名称即可。
# 重定向
重定向需要使用Flask的redirect函数来实现,使用from flask import Flask,url_for,redirect来导入该函数
示例:
from flask import Flask,url_for,redirect
import config
app = Flask(__name__)
app.config.from_object(config)
@app.route('/index/<id>')
def index(id): # 这里的id需要和上面的<id>名称一样
print(url_for('user_list'))
# return "你请求的参数是:{id}".format(id=id)
# 1、直接使用return redirect('url地址')的方式重定向
# return redirect("/userlist") # 跳转到user_list页面
# 2、使用url_for的方式重定向
ulist = url_for("user_list") # 注意这里写的函数名称,并不是route里的请求地址
return redirect(ulist)
@app.route('/userlist/')
def user_list():
return "this is user list page"
if __name__ == '__main__':
app.run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
当访问http://127.0.0.1:5000/index/12345 (opens new window)后,会跳转到userlist页面
# 模板和参数
Flask中使用render_template函数来渲染模板
render_template('html文件名称', 传递给前台的值),例如:return render_template('index.html',**content)
# 导入render_template
from flask import Flask,render_template
@app.route('/<username>')
def username(username):
# 给前台传递参数的方式
# 方式1: 直接在render_template中填写username参数
return render_template('index.html',username=username)
# 方式2: 可以使用一个字典对象
# content = {
# 'username': u'张三',
# 'gender': u'男',
# 'age': 18
# }
# return render_template('index.html',**content)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在项目根目录下的templates中新建一个index.html文件即可
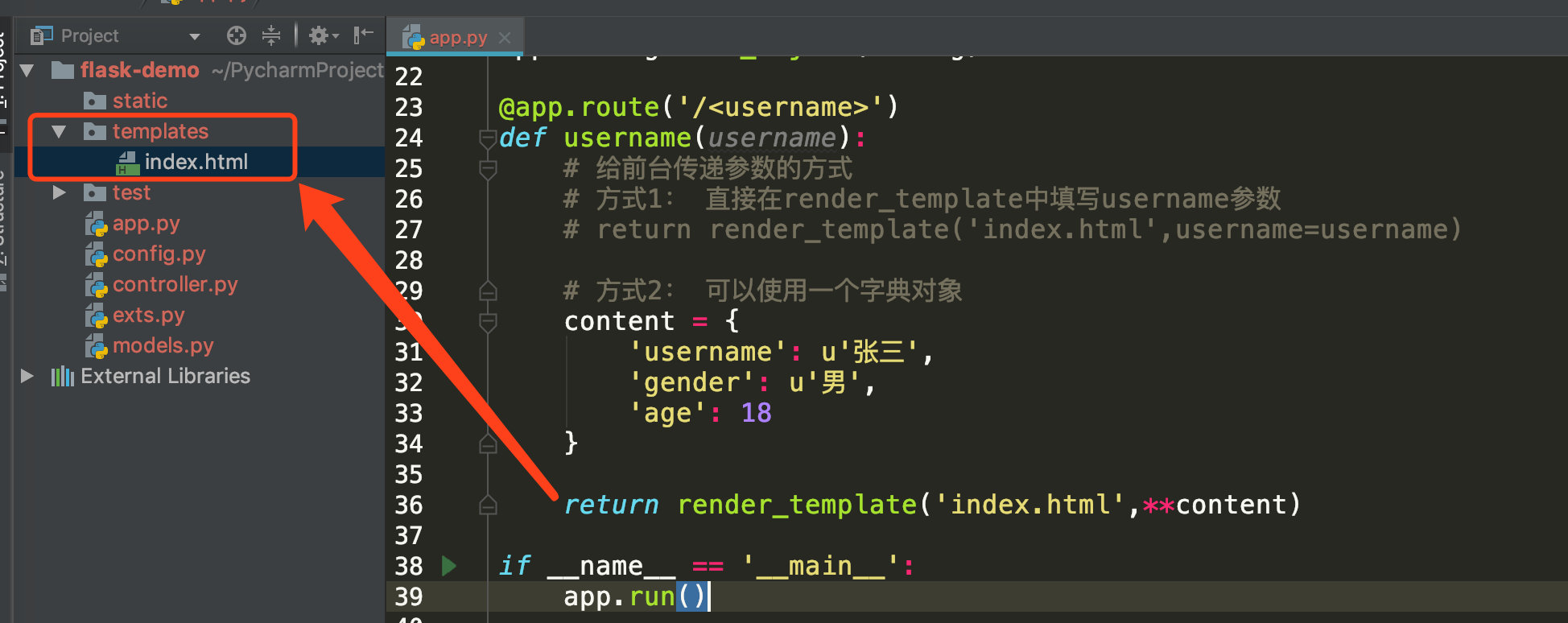
templates/index.html文件内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
this is index 文件<br>
<hr>
姓名:{{ username }} </br>
性别:{{ gender }}</br>
年龄:{{ age }}</br>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
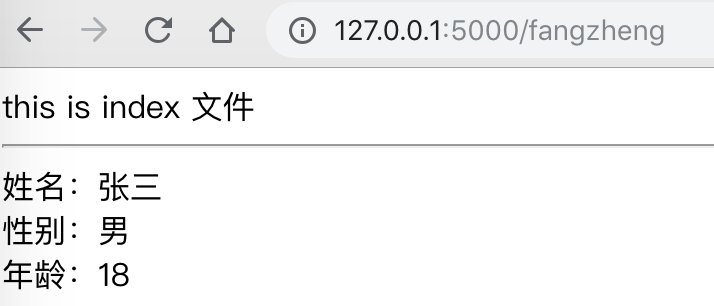
访问http://127.0.0.1:5000/fangzheng 时,会得到如下页面。
访问字典数据 如果后台传递的值是字典类型:
@app.route('/<username>')
def username(username):
# 给前台传递参数的方式
# 方式1: 直接在render_template中填写username参数
# return render_template('index.html',username=username)
# 方式2: 可以使用一个字典对象
content = {
'username': u'张三',
'gender': u'男',
'age': 18,
'websites': {
'baidu': 'www.baidu.com',
'google': 'www.google.com'
}
}
return render_template('index.html',**content)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
index.html访问字典中内容
<hr>
{{ websites.baidu }}<br>
{{ websites.google }}
2
3
页面显示内容:
this is index 文件
姓名:张三
性别:男
年龄:18
www.baidu.com
www.google.com
2
3
4
5
6
# Jinja2模板引擎
# 打印变量
在jinja2中打印变量很简单,直接使用两个大括号即可
<a href="#">{{ user.username }}</a>
# if语句
jinja2的if语法也很简单,需要大括号和百分号包裹起来
{% if *** %}
{% else %}
{% endif %}
2
3
4
5
后台Python代码如下:
@app.route('/<is_login>/')
def login(is_login):
if is_login == '1':
user = {
'username':'张三',
'age':18
}
return render_template('login.html',user=user)
else:
return render_template('login.html')
2
3
4
5
6
7
8
9
10
前台html代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
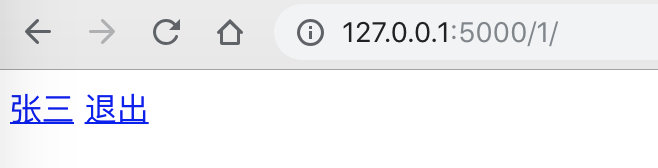
{% if user %}
<a href="#">{{ user.username }}</a>
<a href="#">退出</a>
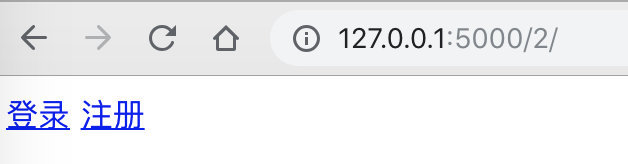
{% else %}
<a href="#">登录</a>
<a href="#">注册</a>
{% endif %}
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
浏览器中请求,1表示登录,其他表示未登录
# for语句
for的语法和Python基本一样
遍历字典
实例:
后台Python代码如下:
@app.route('/index/')
def username():
# 给前台传递参数的方式
# 方式1: 直接在render_template中填写username参数
# return render_template('index.html',username=username)
# 方式2: 可以使用一个字典对象
content = {
'username': u'张三',
'gender': u'男',
'age': 18,
'websites':{ # 字典类型
'baidu':'http://www.baidu.com',
'google': 'http://www.google.com'
},
'users': [ # 列表类型
{'username':u'张三','age':18},
{'username':u'李四','age':28},
{'username':u'王五','age':38},
]
}
return render_template('index.html',**content)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
前台html代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
this is index 文件<br>
<hr>
姓名:{{ username }} </br>
性别:{{ gender }}</br>
年龄:{{ age }}</br>
{{ websites.baidu }}<br>
{{ websites.google }}
<br>
<hr>
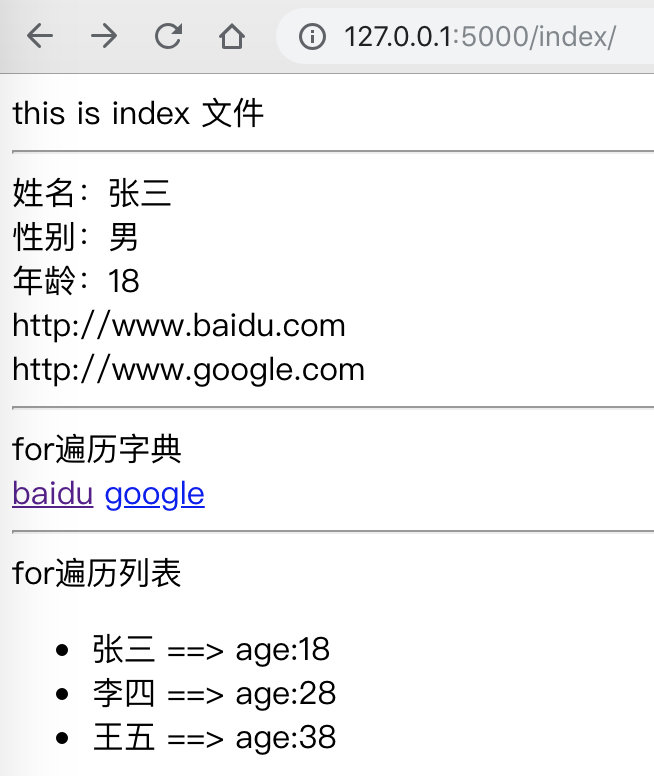
for遍历字典
<br>
<!-- {% for k,v in websites.items() %}
<a href="{{ v }}">{{ k }}</a>
{% endfor %} -->
<hr>
for遍历列表
<br>
<ul>
<!-- {% for user in users %}
<li>{{ user.username }} ==> age:{{ user.age }}</li>
{% endfor %} -->
</ul>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
访问http://127.0.0.1:5000/index/ 后的效果如下:
# 过滤器
过滤器的作用类似于if语句,可以处理一些变量,把原始的变量经过过滤器处理后,再展示处理后的变量值
default过滤器
语法如下: 表示如果username不存在,就显示游客。
{{ username | default{'游客'} }}
length过滤器
语法如下: 表示显示users变量的长度
{{ users | length}}
# Jinja2的继承
Jinja2的继承表示模板的继承,子页面继承父页面的结构,从而实现代码的复用。不用写重复的代码。
语法如下:
父模板中就正常写代码,然后留一些block块给子页面用,让子页面来填充该block内容
后台代码如下
@app.route('/')
def index():
return render_template('index.html')
@app.route('/login/')
def login():
return render_template('login.html')
2
3
4
5
6
7
base.html内容如下:父页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
body{
color:red
}
.nav{
hight:100px;
background:#F98334;
}
</style>
</head>
<body>
<div class="nav">
<ul>
<li>
<a href="/">首页</a>
<a href="#">登录</a>
</li>
</ul>
</div>
{% block main %}
<h1>这是首页</h1>
<a href="{{ url_for('login')}}">登录</a>
{% endblock %}
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
login.html内容如下:子页面
登录页面是子页面,通过extends关键字继承父模板index.html,然后又写了个block main来填充父模板中留的块内容。实现的效果就是不同页面展示不同的h1
{% extends 'index.html' %}
{% block main %}
<h1>这是登录页</h1>
{% endblock %}
2
3
4
5
6
7
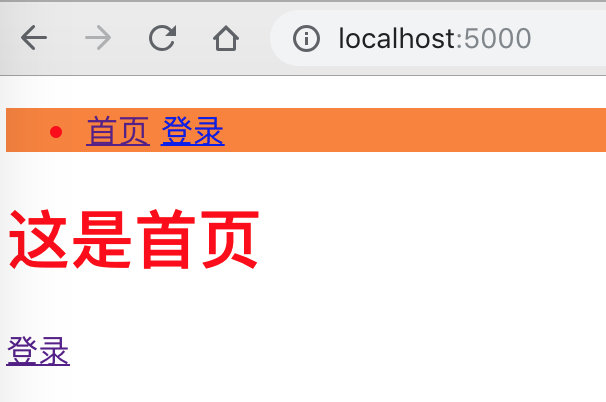
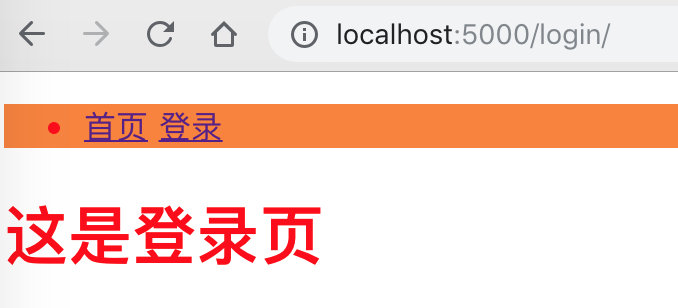
# URL链接
在Flask中,可以使用url_for的方式进行反转链接,以下url_for(login)的方式相当于http://localhost:5000/login/ 链接
<a href="{{ url_for('login') }}">登录</a>
# 加载静态文件
Flask默认会从static路径下加载静态文件,所以不用再加static目录前缀了,使用url_for的方式加载即可。
<link rel="stylesheet" href="{{ url_for('static',filename='css/index.css') }}">
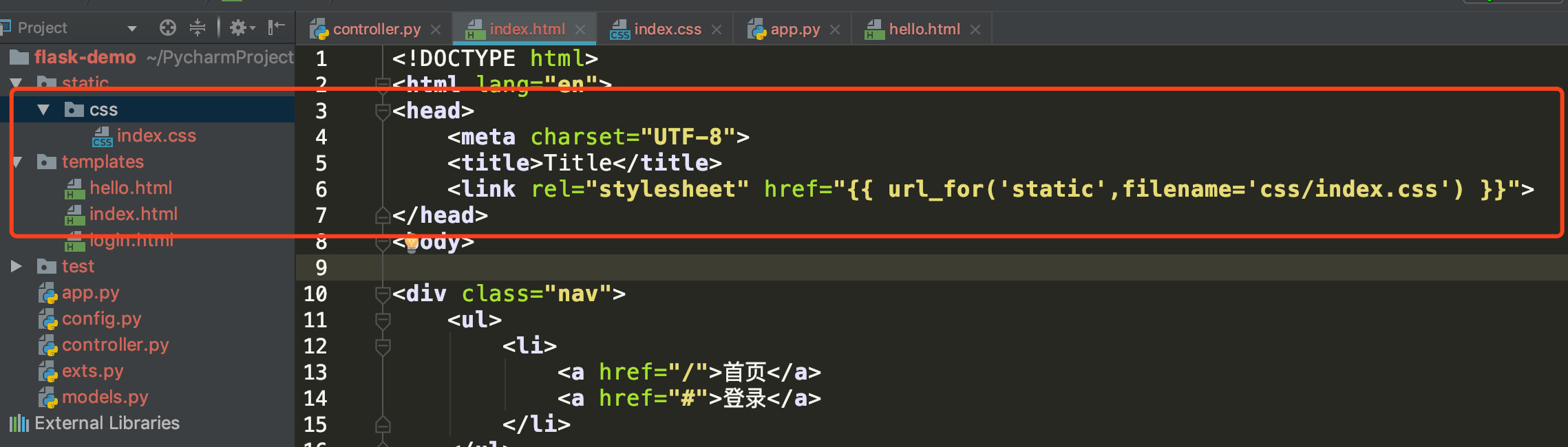
# Flask-SQLAlchemy
在 Flask 中,为了简化配置和操作,我们使用的 ORM 框架是 Flask-SQLAlchemy (opens new window),这个 Flask 扩展封装了 SQLAlchemy (opens new window) 框架。在 Flask-SQLAlchemy 中,数据库使用 URL 指定,下表列出了常见的数据库引擎和对应的 URL
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite (Unix) | sqlite:////absolute/path/to/database |
| SQLite (Windows) | sqlite:///c:/absolute/path/to/database |
廖雪峰讲SQLAlchemy (opens new window)
sqlalchemy学习笔记 (opens new window)
Flask 插件系列 - Flask-SQLAlchemy (opens new window)
# 安装
通过pip安装
pip install flask-sqlalchemy
# 连接到SQLite数据库
使用SQLAlchemy之前,需要先配置数据库连接,这里需要在一个固定的变量SQLALCHEMY_DATABASE_URI里配置数据库的URI配置。
以下是一个简单的 和SQLite 数据库连接的示例:
# -*- coding: utf-8 -*-
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///db/users.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
# db 对象是 SQLAlchemy 类的实例,表示程序使用的数据库。
db = SQLAlchemy(app)
class User(db.Model):
"""定义数据模型,一个模型就是一个class,对应数据库中一张表"""
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email
def __repr__(self):
return '<User %r>' % self.username
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 连接到MySQL数据库
这次我们使用一个config.py文件来统计管理数据库相关的配置
config.py文件内容如下:
# DEBUG模式
DEBUG = False
# SECRET_KEY
# SQLALCHEMY
DIALECT = 'mysql'
DRIVER = 'pymysql'
USERNAME = 'root'
PASSWORD = 'fangzheng'
HOST = '127.0.0.1'
PORT = 3306
DATABASE = 'test'
# SQLALCHEMY_DATABASE_URI是固定的变量名
SQLALCHEMY_DATABASE_URI = "{}+{}://{}:{}@{}:{}/{}?charset=utf8".format(DIALECT,DRIVER,USERNAME,PASSWORD,HOST,PORT,DATABASE)
# 为了防止控制台的一个警告
SQLALCHEMY_TRACK_MODIFICATIONS = False
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
然后在app.py中使用SQLAlchemy,需要先from flask_sqlalchemy import SQLAlchemy导入该包,然后我们的配置信息在config.py中,所以也需要导入进来
app.py文件内容如下:
from flask import Flask,render_template
from flask_sqlalchemy import SQLAlchemy
from exts import app,db
import config
# 加载配置文件
app.config.from_object(config)
# 验证数据库连接是否正确
db = SQLAlchemy(app)
# 模型:归档模型,对应数据库中的article表
class Article(db.Model):
__tablename__ = 'article'
id = Column(db.Integer,primary_key=True,autoincrement=True)
title = Column(db.String(100),nullable=False)
content = Column(db.Text,nullable=False)
# 模型:User对应数据库中的User表
class User(db.Model):
__tablename__ = 'user'
id = Column(db.Integer,primary_key=True,autoincrement=True,comment='自增id')
username = Column(db.String(100),nullable=False,comment='用户名')
password = Column(db.Text,nullable=False,comment='密码')
email = Column(db.String(50),nullable=False,comment='邮箱')
# 使用create_all方法可以直接创建表,也可以验证数据库连接是否正确,如果不报错表示连接正确。
db.create_all()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
运行app.py文件,控制台不报错即是连接成功。
# Flask-SQLAlchemy模型映射
上面的app.py代码中使用了create_all()方法可以自动根据模型在你数据库中帮你帮你自动创建表
# Flask-SQLAlchemy增删改查
@app.route('/index')
def index():
# 数据的增删改查
# 增加
article = Article(title='title1',content='concent111')
db.session.add(article) # 将数据添加到会话中
db.session.commit() # 提交事务
# 查询:select * from article where title='title1';
article = Article.query.filter(Article.title == 'title1' ).all()
for a in article:
print(a.title,a.content) # 打印:title1 concent111
# # 改:先把需要改的数据查出来,然后修改,最后再把修改后的数据进行事务提交
article = Article.query.filter_by(id=1).first()
print(article.title)
article.title = 'new title12334'
print(article.title)
# 提交事务
db.session.commit()
# 删除
# 先查询出数据对象,然后删除,最后提交事务
article = Article.query.filter_by(id=2).first()
db.session.delete(article)
db.session.commit()
return render_template('index.html')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Flask-Script
Flask-Script的作用是可以通过命令行的方式操作flask,例如:通过命令启动flask应用,通过命令行migrate迁移表。
安装:使用pip install flask-script命令安装即可,建议在虚拟环境中安装。
安装完成后,建立一个manager.py文件,用来处理命令行的命令。
manager.py文件内容如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from flask_script import Manager
from db_scripts import DBManager
from exts import app
# 这里的app是flask的app
manager = Manager(app)
# 下面这个@manager需要和上面的manager变量名称保持一致!!!
@manager.command
def runserver():
# 模拟服务器启动
print('服务器启动成功....')
# 添加数据库相关的命令db_scripts.py
manager.add_command('db',DBManager)
if __name__ == '__main__':
manager.run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
以上代码是模拟了一个服务器启动的命令runserver
然后再封装一个数据库操作相关的文件db_scripts.py
db_scripts.py文件内容如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from flask_script import Manager
## 由于不用启动db_scripts.py这个文件,所以就不用传app对象了
DBManager = Manager()
@DBManager.command
def init():
print('数据库初始化完成...')
@DBManager.command
def migrate():
print('数据库表迁移成功...')
## 这里也不用像manager.py中那样manager.run()了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
接下来运行manager.py文件即可
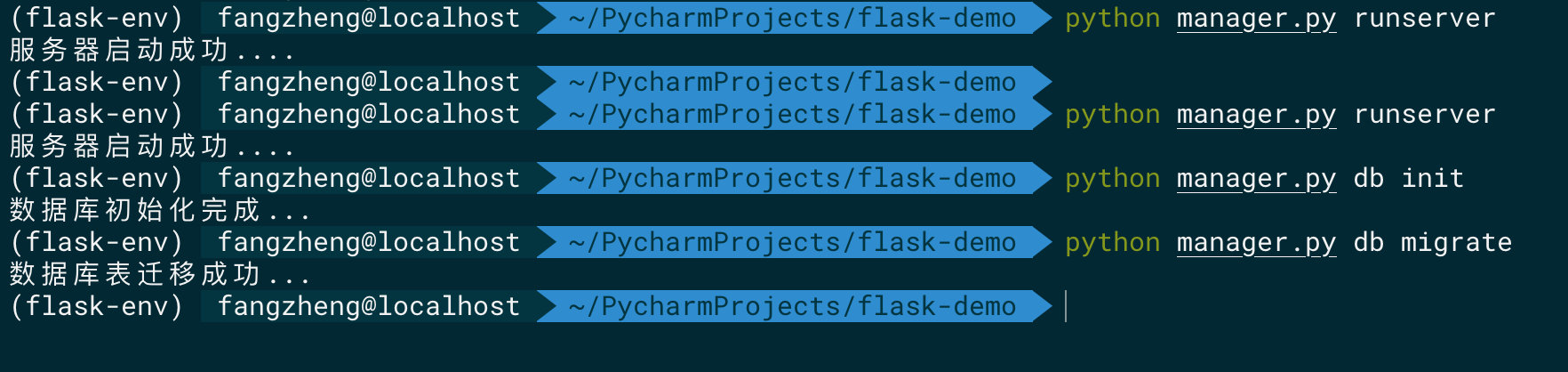
启动虚拟环境,然后执行python manager.py runserver查看效果
fangzheng@localhost $ source activate
(flask-env) fangzheng@localhost $ python manager.py runserver
(flask-env) fangzheng@localhost $ python manager.py db init
(flask-env) fangzheng@localhost $ python manager.py db migrate
2
3
4
效果如下:类似于django
# Flask-Migrate
在以前的代码中,我们的model类的代码拆分出来在models.py中了,但是如果表结构更改后,是不会自动更新到数据库中的,一种解决办法就是:先drop table,然后再使用flask的db.create_all()方法来重新建表。显然这样的方式不太好。这时候,可以使用Flask-Migrate来解决。Flask-Migrate插件是基于Alembic,Alembic是由大名鼎鼎的SQLAlchemy作者开发数据迁移工具。专门来解决数据库迁移的问题。
flask-migrate官网 (opens new window)
# 安装
pip install Flask-Migrate
添加mirgate相关的command到manager.py文件中
Manager.py
from app import create_app, db
from app.models import Users , Users_detail #注册数据库模型【【注意:这里一定要注册!!】】
from flask_script import Manager, Shell
from flask_migrate import Migrate, MigrateCommand #载入migrate扩展
app = create_app('default')
manager = Manager(app)
migrate = Migrate(app, db) #注册migrate到flask
manager.add_command('db', MigrateCommand) #在终端环境下添加一个db命令
if __name__ == '__main__':
manager.run()
2
3
4
5
6
7
8
9
10
11
12
13
# 初始化
python manage.py db init
这里的 init 只需要执行一次,以后的修改都不用执行了。同时当执行完init命令后,会在你项目根目录下创建一个migrations文件夹,里面存放了所有迁移脚本。
# 迁移
python manager.py db migrate -m "initial migrateion"
- 其中-m表示添加提交版本信息的注释内容
在Alembic,数据库迁移工作由迁移脚本完成。这个脚本有两个函数,分别叫做upgrade()和downgrade()
upgrade():函数实施数据库更改,是迁移的一部分
downgrade():函数则删除它们。通过添加和删除数据库变化的能力,Alembic可以重新配置数据库从历史记录中的任何时间点。将迁移中的改动从数据库中删除,即具有回滚到某个迁移点的功能。
该步骤还会在数据库中生成alembic_version表,该表作为flask-migrateion的迁移记录表。
# 应用迁移
使用upgrade命令将迁移中的改动应用到数据库中
python manage.py db upgrade
所以正确的使用顺序是:
- 使用
init命令python manage.py db init初始化数据库和表(只执行一次即可) - 使用
migrate命令python manager.py db migrate -m "initial migrateion"命令来生成迁移的py文件 - 使用
upgrade命令python manage.py db upgrade来把迁移文件中的内容(修改的ddl内容)应用到数据库中
# Flask的models循环引用的问题
之前我们写的代码里是直接在app.py中写的model模型类(Article),但是如果项目越来越大,这个model类会越来越多,代码臃肿。所以我们需要拆分代码,类似于java中的代码分层service、dao、bean之类的分包。
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///./Article.db'
SQLALCHEMY_TRACK_MODIFICATIONS = False
db = SQLAlchemy(app)
class Article(db.Model):
__tablename__='article'
id = db.Column(db.Integer,primary_key=True)
title = db.Column(db.String(100),nullable=False)
content = db.Column(db.Text,nullable=False)
# class1
# class2
# .....
# db.create_all()
@app.route('/')
def index():
return 'index'
if __name__ == '__main__':
app.run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
拆分出models.py文件
新建models.py文件,把模型类放到models.py中,但是会出现循环引用的问题。
依赖关系如下:
主app.py文件中依赖models.py,models.py中依赖主app.py里的db对象
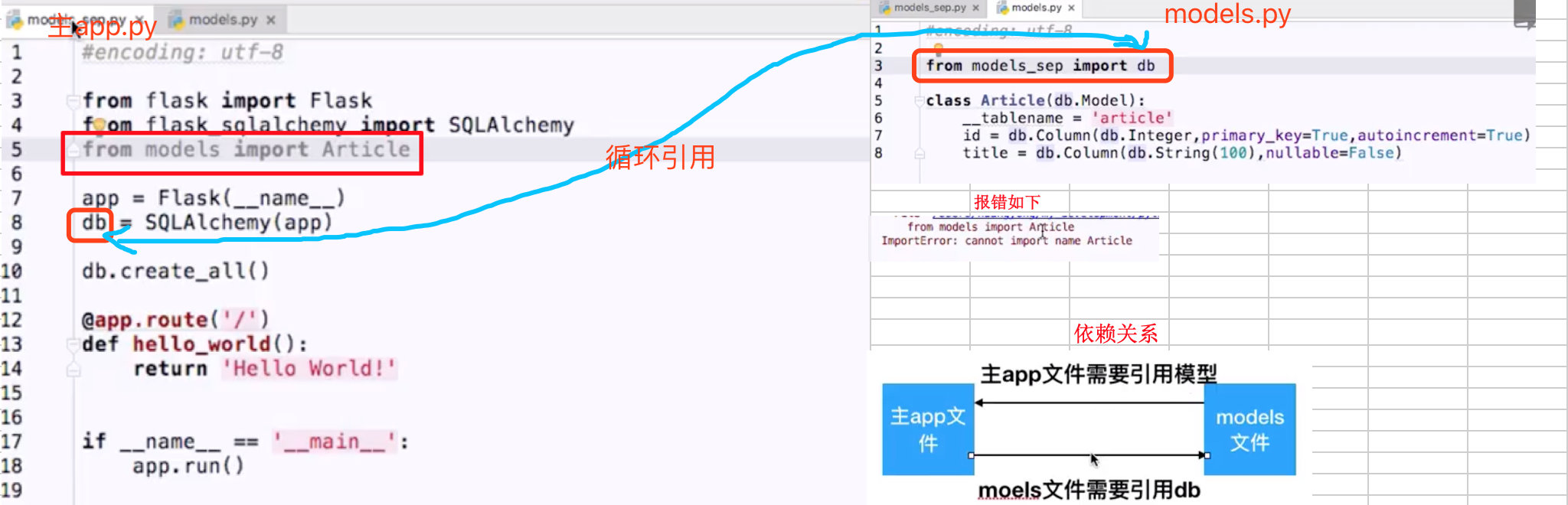
解决办法
解决办法就是把循环引用的对象提取出来,放到另外的对象中。
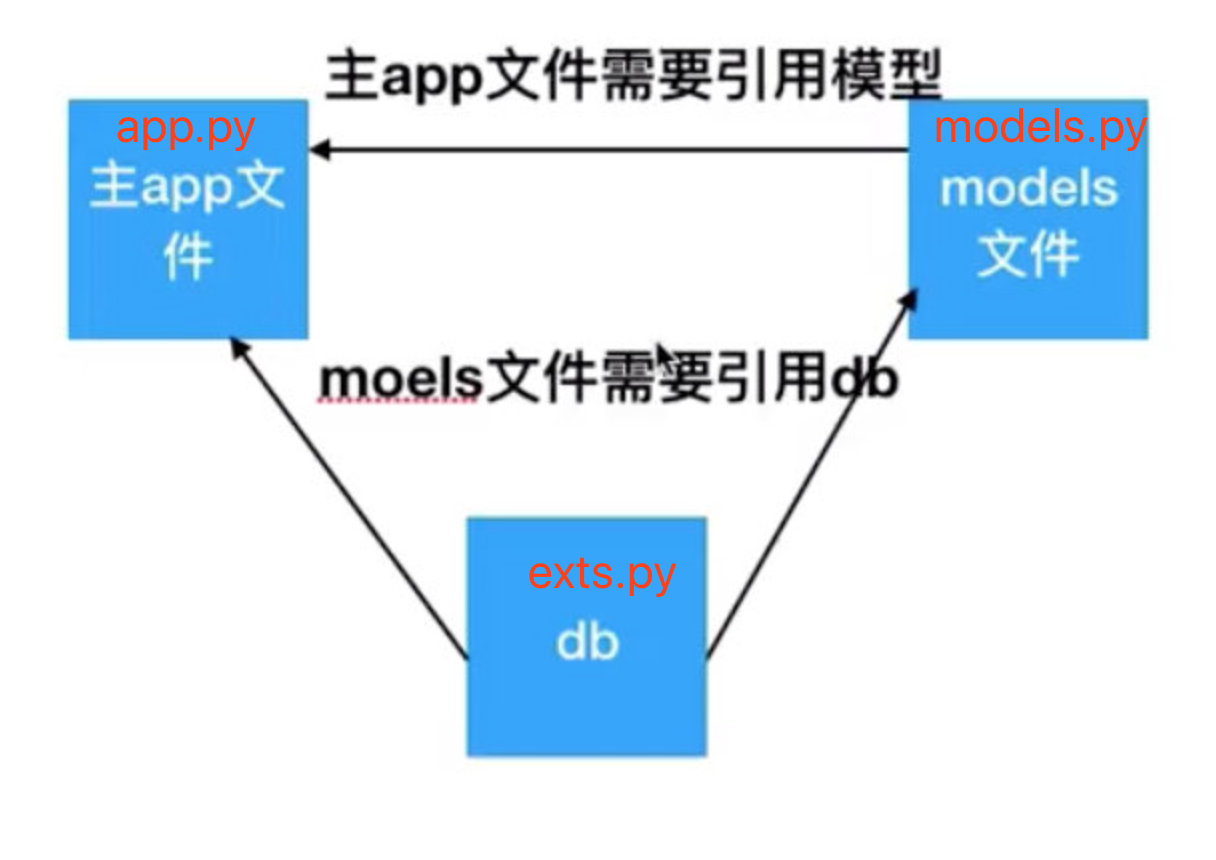
代码结构如下图:
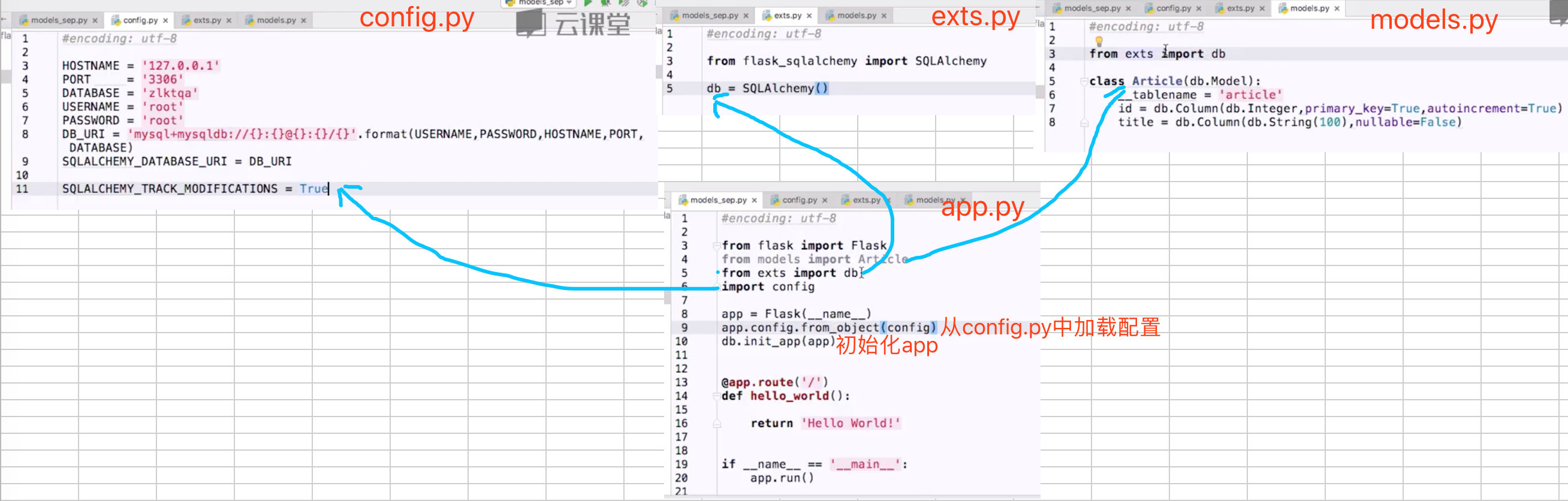
# Flask-Cookie
cookie的概念就不说了,这里直接说在flask中如何使用cookie,由于cookie是保存在浏览器中的,只需要知道概念即可,真正的操作是在前端js中操作。
# Flask-Session
在操作flask-session之前,需要先设置SECRET_KEY,这个SECRET_KEY主要是为了加密用的,可以理解为md5算法中加入盐的道理。
在config.py中添加SECRET_KEY
SECRET_KEY = "ijsdng238afks" # 任意24个字符长度的字符串即可
# 也可以使用os模块中的urandom方法生成一个24位的随机字符串
import os
SECRET_KEY = os.urandom(24)
2
3
4
# flask中操作session
操作session跟操作python中的字典类型一样
from flask import Flask,render_template,session
from exts import app,db
from models import User,Article
@app.route('/index')
def index():
# 添加
session['username'] = 'zhangsan'
# 读取:
print(session['username']) # 方式1:如果username不存在,会抛出异常。
print(session.get('username')) # 方式2【推荐】:如果username不存在,会返回一个null而不抛出异常
# 删除
session.pop('username') # 删除指定session
session.clear() # 删除session中的所有数据
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Get和Post请求
get和post请求的介绍就不说了,主要说如何使用,以及如何获取相应请求的参数。
# Get
通过flask的request对象的args来获取
request.args
# Post
通过flask的request对象的form来获取
request.form
实例代码如下:
app.py
from flask import Flask,render_template,session,request
from exts import app,db
from models import User,Article
# db.create_all()
# Get请求,默认情况是使用Get请求
@app.route('/search/')
def search():
# 获取get请求的参数
print(request.args)
print(request.args.get('username')) # args是一个字典类型,所以可以直接使用get方法来获取参数
return 'search'
# post请求
@app.route('/login/',methods=['GET','POST'])
def login():
if request.method == 'GET':
print('get请求')
else:
print('post请求')
# 获取post请求的参数
print(request.form.get('username'))
print(request.form.get('password'))
return render_template('login.html')
if __name__ == '__main__':
app.run(debug=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
login.html
<form action="{{ url_for('login') }}" method="post">
<span>用户名:</span><input type="text" name="username">
<span>密 码:</span><input type="password" name="password">
<input type="submit" value="提交">
</form>
2
3
4
5
# g(global)对象
g对象是专门用来保存用户的数据的。
g对象在一次请求中的所有的代码的地方,都是可以使用的。
从flask中导入from flask import Flask,g
# Get请求,默认情况是使用Get请求
@app.route('/search/')
def search():
# 获取get请求的参数
print(request.args)
username = request.args.get('username') # args是一个字典类型,所以可以直接使用get方法来获取参数
g.username = username # 把username放到g对象里,这样在其他任何地方都能获取到该g对象里的username属性了
return 'search'
2
3
4
5
6
7
8
# 钩子函数
钩子函数是指在执行函数和目标函数之间挂载的函数, 框架开发者给调用方提供一个point -挂载点, 至于挂载什么函数有我们调用方决定, 这样大大提高了灵活性。
在程序正常运行的时候,程序按照A函数—->B函数的顺序依次运行;钩子函数可以插入到A函数到B函数运行中间从而,程序运行顺序变成了A—->钩子函数—->B函数。
常用的钩子函数
# before_first_request
before_first_request 处理第一次请求之前执行
# 服务器被第一次访问执行的钩子函数
@app.before_first_request
def first_request():
print("first time request")
2
3
4
# before_request
before_request 在每次请求之前执行. 通常使用这个钩子函数预处理一些变量, 视图函数可以更好调用
# 在服务器接收的请求还没分发到视图函数之前执行的钩子函数
@app.before_request
def before_request():
# print("我勾住了每次请求")
user_id = session.get("user_id")
if user_id:
g.user = "DaYe"
2
3
4
5
6
7
# context_processt
context_processor 上下文处理器, 返回的字典可以在全部模板中使用
@app.context_processor()
def context():
# 必须返回一个字典
# hasattr(obj, attr) 判断obj是否有attr属性, 注意此时的attr应该是字符串
if hasattr(g, "user"):
return {"current_username": "DaYe"}
else:
# 注意: 必须返回一个字典
return {}
2
3
4
5
6
7
8
9
# teardown_appcontext
teardown_appcontext 当APP上下文被移除之后执行的函数, 可以进行数据库的提交或者回滚
@app.teardown_appcontext
def teardown(exc=None):
if exc is None:
db.session.commit()
else:
db.session.rollback()
db.session.remove()
2
3
4
5
6
7
# template_filter
template_filter, 增加模板过滤器
@app.template_filter
def upper_filter(s):
return s.upper()
2
3
# errorhander
errorhander, 在发生一些异常时, 比如404错误, 就会自动调用对应的钩子函数
- 发生请求错误时, 框架会自动调用相对钩子函数, 并向钩子函数传入
error参数 - 如果钩子函数没有定义
error参数, 就会报服务器错误 - 开发者可以通过
flask.abort方法手动抛出异常, 比如发现输入的参数错误可以使用abort(404)来解决
@app.errorhander(404)
def page_not_found(error):
return render_template("error400.html"), 404
@app.errorhander(500)
def server_error(error):
return render_template("error505.html"), 500
2
3
4
5
6
7