
 Hive的DDL语句
Hive的DDL语句
# 1. Hive的DDL
DDL(Data Definition Language)是数据定义语言,表示创建和修改一些数据库、表、视图等操作。
Hive的一些特点:
- Hive不支持行级别的操作(插入、更新、删除),也不支持事务
- Hive中的数据库本质上仅仅是HDFS的一个目录,数据库中的表将会以这个数据库目录子目录的形式存储
- 如果用户没有指定数据库,Hive将会使用默认的数据库default
- 数据库的目录位于属性hive.metastore.warehouse.dir所指定的顶层目录之后
- 数据库的文件目录名是以.db结尾的
- Hive的master-server依据hadoop配置文件中fs.default.name作为master-server的服务器名和端口号
- 默认情况下,Hive不允许删除一个包含表的数据库,如果需要级联删除,需加关键字cascade
- Hive中关键字table和schema是含义相同
- Hive会自动为表增加两个属性:last_modified_by和last_modified_time
- 如果不想使用默认表路径,为了避免产生混淆,建议使用外部表 相对于外部表而言是管理表,Hive会控制着管理表的数据的生命周期;Hive删除管理表会同时删除其数据,如果和其他工作共享数据,则使用外部表,创建一个表指向外部数据,但是并不需要对其具有所有权,删除表时并不会删除数据
- 防止用户对分区表误操作,没有添加分区过滤器(where谓词)从而触发一个巨大的MapReduce任务,可以将Hive设置为'strict'模式:set hive.mapred.mode=strict
- 用户不小心删除的数据会移到用户根目录的.Trash目录下,不过需要开启HDFS的回收站功能需要配置fs.trash.interval=1440,1440是回收站检查点的时间间隔,单位是分钟
# 1.1 Hive的CLI操作
# 1.1.1 在CLI中使用Hadoop的dfs命令
在CLI中使用hdfs的命令,只要把hadoop dfs -ls /中的hadoop给去掉即可。
并且:以这种方式访问HDFS更高效,因为Hive会在同一个进程中执行这些dfs命令

# 1.1.2 在CLI中显示数据库名
set hive.cli.print.current.db=true;
显示效果如下:

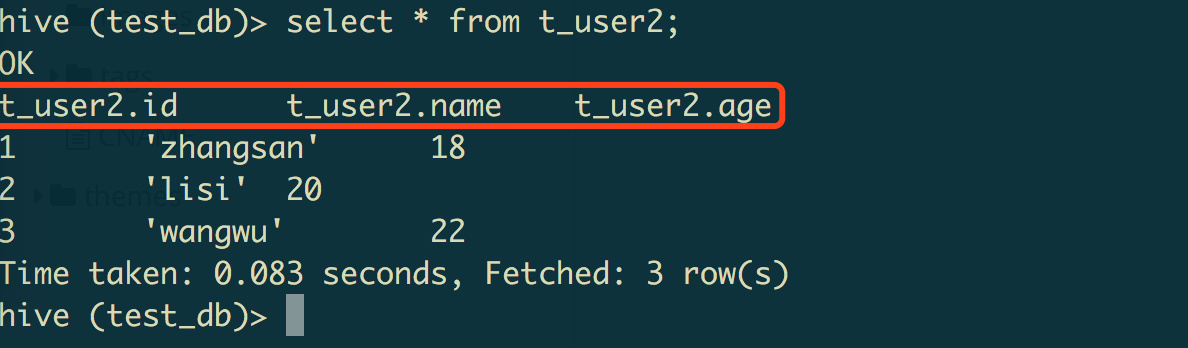
# 1.1.3 在CLI中显示SELECT字段名称
set hive.cli.print.header=true;
显示效果如下:
# 1.1.4 在CLI中执行shell命令
在CLI中使用shell,只要在命令前加上!,命令以;结尾即可

# 1.1.5 在shell中执行hive命令
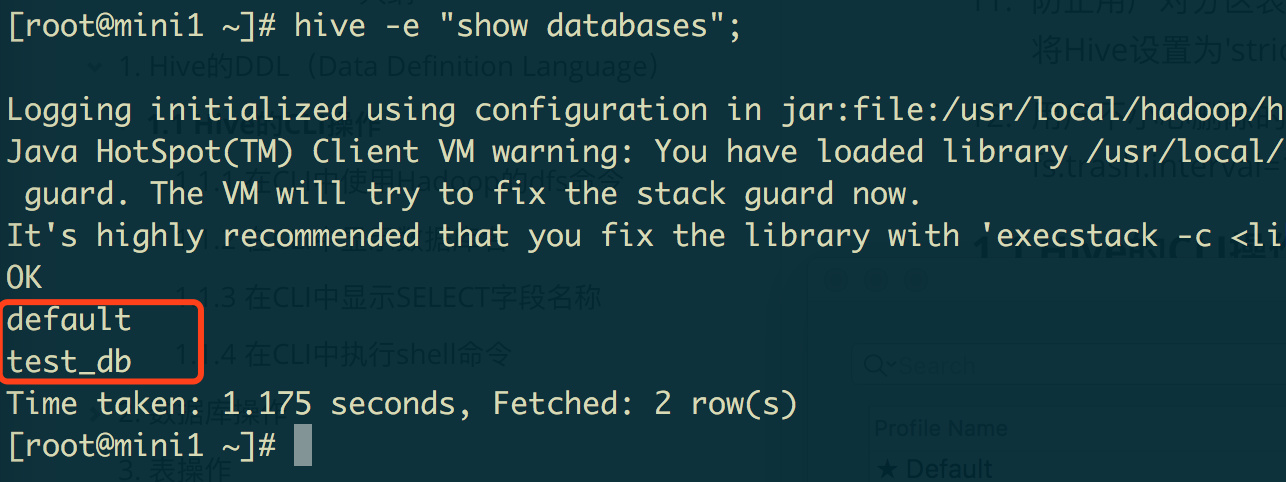
如果要直接在shell命令提示符下执行hive命令,只要使用hive -e选项即可。
例如:显示所有数据库
[root@mini1 ~]# hive -e "show databases";
或者使用hive -S -e选项
Hive命令的具体选项如下:
- -S :表示开启静默模式,这样可以在输出结果中去掉“OK”和“Time taken”等行。
- -e :表示执行一条SQL
- -f :表示执行一个SQL文件
# 1.1.6 Hive执行sql文件
如果要执行一个sql文件,可使用-f选项。一般约定,hive的sql文件以hql结尾。
例如:hive -f /root/init.hql
$ hive -f /root/init.hql
如果是在CLI交互环境下,可以使用source命令来执行一个sql文件
hive> source /root/init.hql
# 2. 数据库操作
# 2.1 创建数据库
--创建数据库并添加注释
create database test_db comment 'test datebase';
--创建数据库如果不存在的话
create database if not exists test_db comment 'test database';
--创建数据库,指定数据库存储位置
create database test_db location '/hive/db/directory';
--创建数据库,添加相应的数据库属性
create database test_db with dbproperties ('creator' = 'user', 'date' = '20151010');
2
3
4
5
6
7
8
# 2.2 查看数据库
--查看hive中所有的数据库
show databases;
--查看hive中以h.开头的数据库
show databases like 'h.*';
--查看数据库的详细信息
describe database test_db;
--查看数据库的详细信息
describe database extended test_db;
2
3
4
5
6
7
8
# 2.3 切换数据库
use test_db;
# 2.4 删除数据库
--删除数据库:该数据库必须是空的
drop database if exists test_db;
--删除数据库和该数据库下的所有表
drop database if exists test_db cascade;
2
3
4
# 2.5 显示数据库中的表
show tables;
show tables in test_db;
show tables 'test.*';
2
3
# 3. 表操作
由于Hive中数据是存放在HDFS中的,所以Hive建立表的列需要和HDFS字段保持一致。
# 3.1 Hive表的类型
# 3.1.1 管理表
管理表又称为内部表,这种表会被Hive控制着数据的生命周期,当在hive>drop表时,也会将数据一并删除。
管理表中的数据存放在了HDFS的/user/hive/warehouse/目录下
使用常见的建表语句创建的表就是管理表,或者叫内部表。
# 3.1.2 外部表
外部表的意思就是Hive表的数据不存储在/user/hive/warehouse/目录下,而是存储在外部的一个路径下(例如:HDFS的某个路径下)
创建外部表很简单。例如:我们创建一个数据位于/data/stocks目录下以逗号分隔的一张表
CREATE EXTERNAL TABLE IF NOT EXISTS STOCKS(
EXCHANGE STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION '/data/stocks';
2
3
4
5
6
以上SQL表示创建一张数据存储在/data/stocks目录下以逗号分隔的一张外部表。
因为是外部表,所以Hive认为并不认为其完全拥有这份数据,所以是hive删除表的时候,只删除元数据信息,真实的数据文件/data/stocks并不会被删除。
# 3.1.3 分区表
Hive也支持表的分区,分区是为了更方便的管理数据。例如:按时间分区,这样每天的日期一个分区。
创建分区表也很简单,只需要在建表的create table语句中加上一句:partitioned by (date string)即可
例如:如下表将会按照给定的date字段建立分区
create table table_name (
id int,
dtDontQuery string,
name string
)
partitioned by (date string)
2
3
4
5
6
如果需要建立多个分区,则只需要把分区字段列出即可。PARTITIONED BY(dt STRING, country STRING)
注意
分区字段可以不是表中的字段,但是可以当做普通字段来使用。
# 3.1.3.1 静态分区
Hive的静态分区很简单,就是partition(dt=20180611),而这个日期20180611就是静态分区的值
如下SQL表示使用静态分区的方式向分区表中插入数据,插入的所有数据都属于这个dt=20180611分区
INSERT OVERWRITE TABLE dw.dwd_oms_buss_coupon_person_due partition (dt=20180611)
select
....
from table_name
2
3
4
# 3.1.3.2 动态分区
动态分区:动态的插入分区
如果插入少量的分区可以使用静态分区的方式,但是如果需要插入大量的分区。假设要用一张表中的所有城市交易日期当做分区,则可以使用动态分区的方式。
实例:
INSERT OVERWRITE TABLE dw.dwd_oms_buss_coupon_person_due partition (dt)
select
....
dt
from table_name
2
3
4
5
动态分区会根据select语句后面的字段来对应分区字段,例如上面的dt分区会根据select语句的最后一个dt字段的值来建立动态分区。
# 3.1.4 表的存储格式
Hive支持内置的和自定义的数据存储格式,其中内置的格式如下:
| Storage Format | Description |
|---|---|
| STORED AS TEXTFILE | 【常用】文本格式是Hive默认的存储格式,可以通过hive.default.fileformat来修改默认存储格式。默认存储格式使用的类是 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
| STORED AS SEQUENCEFILE | Stored as compressed Sequence File. |
| STORED AS ORC | 【常用】ORC格式为压缩格式,压缩格式的表会占用较小的存储空间。ORC格式的表不支持load data local inpath 方式导入数据。 |
| STORED AS PARQUET | Stored as Parquet format for the Parquet (opens new window) columnar storage format in Hive 0.13.0 and later (opens new window); Use ROW FORMAT SERDE ... STORED AS INPUTFORMAT ... OUTPUTFORMAT syntax ... in Hive 0.10, 0.11, or 0.12 (opens new window). |
| STORED AS AVRO | Stored as Avro format in Hive 0.14.0 and later (opens new window) (see Avro SerDe (opens new window)). |
| STORED AS RCFILE | Stored as Record Columnar File (opens new window) format. |
| STORED BY | Stored by a non-native table format. To create or link to a non-native table, for example a table backed by HBase (opens new window) or Druid (opens new window)or Accumulo (opens new window). See StorageHandlers (opens new window) for more information on this option. |
| INPUTFORMAT and OUTPUTFORMAT | in the file_format to specify the name of a corresponding InputFormat and OutputFormat class as a string literal. For example, 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextInputFormat'. For LZO compression, the values to use are 'INPUTFORMAT "com.hadoop.mapred.DeprecatedLzoTextInputFormat" OUTPUTFORMAT "org.apache.hadoop.hive.ql.io (opens new window).HiveIgnoreKeyTextOutputFormat"' (see LZO Compression (opens new window)). |
常用格式
# 3.1.4.1 TEXTFILE
文本格式的使用方式为:如下表示以文本文件存储,列分隔符是tab键,行分隔符是回车键
CREATE TABLE IF NOT EXISTS dim.dim_high_amt_parking(
city_code string COMMENT '城市编码',
area_code string COMMENT '区代码',
area_name string COMMENT '区名称',
park_name string COMMENT '停车场名称',
park_position string COMMENT '停车场位置',
longitude double COMMENT '经度',
latitude double COMMENT '纬度',
fee_scale DECIMAL(10,2) COMMENT '收费标准(XX元/小时)',
is_night_fee string COMMENT '夜间正常收费(是/否)',
is_cap_fee string COMMENT '是否封顶(是/否) ',
cap_amt DECIMAL(10,2) COMMENT '封顶金额'
) COMMENT '高额停车场'
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'line.delim'='\n',
'serialization.format'='\t')
STORED AS TEXTFILE;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3.1.4.2 ORC
压缩格式
例如:如下表示存储为ORC格式,注意:ORC格式不支持load data local inpath的方式导入数据。
CREATE TABLE IF NOT EXISTS dim.dim_oms_car_peccancy(
peccancy_why_id int COMMENT '违章类型id',
peccancy_why_name string COMMENT '违章类型名称'
) COMMENT '违章类型'
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'line.delim'='\n',
'serialization.format'='\t')
STORED AS ORC;
2
3
4
5
6
7
8
9
10
# 3.1.5 Hive表锁
# 锁介绍
hive 在 0.7 版本之后开始支持并发,线上的环境默认是用 zookeeper 做 hive 的锁管理,Hive开启并发功能的时候自动开启锁功能。
hive 目前主要有两种锁,SHARED(共享锁 S)和 Exclusive(排他锁 X)。共享锁 S 和 排他锁 X 它们之间的兼容性矩阵关系如下:
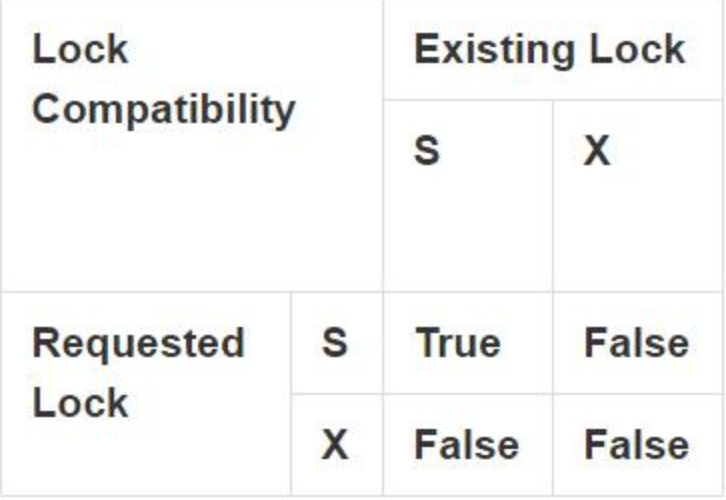
总结起来就是:
- 1)查询操作使用共享锁,共享锁是可以多重、并发使用的
- 2)修改表操作使用独占锁,它会阻止其他的查询、修改操作
- 3)可以对分区使用锁。
# 开启锁
修改hive-site.xml,配置如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>zk1,zk2,zk3</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
2
3
4
5
6
7
8
除此之外,还可以手动显式设置独占锁:
-- 1)锁表
hive> lock table t1 exclusive;
-- 表被独占锁之后,将不能执行查询操作:
hive> SELECT COUNT(*) FROM people;
conflicting lock present for default@people mode SHARED
FAILED: Error in acquiring locks: locks on the underlying objects
cannot be acquired. retry after some time
-- 2)解除锁
hive> unlock table t1;
2
3
4
5
6
7
8
9
10
# 关闭锁
hive的锁在某些情况下会影响job的效率。在对数据一致性要求不高,或者已经明确了解到lock不会对job产生影响的情况下可以在session级别关闭lock的支持,又或者在表被任务循环持续读取时,insert 插入失败(建议脚本重跑一段时间范围数据时设置 sleep 间隔,避免长期持有锁,造成依赖表的任务调度失败)。我们可以通过 set hive.support.concurrency=false 参数在 session 中关闭锁,
提示
set hive.support.concurrency=false这个参数为 false 既能保证session忽略任何锁强行操作数据,又能保证session里的SQL对表不加任何锁.
# 3.1.6. 表常用DDL
--查看当前数据库下所有表
SHOW TABLES;
--查看当前数据库下所有表名以s结尾的表
SHOW TABLES '.*s';
--查看invites表的表结构,或者desc table_name
DESCRIBE invites;
--将表events改名为3koobecaf
ALTER TABLE events RENAME TO 3koobecaf;
--为pokes表添加字段
ALTER TABLE pokes ADD COLUMNS (new_col INT);
--为invites表添加字段,并添加注释
ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
--修改字段名称,注意:字段类型一定要加上!
ALTER TABLE table_name CHANGE old_cloumn_name new_cloumn_name int;
--将invites表的字段替换,相当于重新建表
ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT COMMENT 'baz replaces new_col2');
--删除表
DROP TABLE pokes;
--修改表字段类型或名称
alter table table_name CHANGE old_cloumn_name new_cloumn_name int;
--load本地数据到表中
LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
--load本地数据到表的指定分区中
LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
--查看所有表锁情况
show locks;
--查看指定表锁情况,有数据返回表示表被锁了,反之未锁
show locks youTableName;
--解锁表
unlock table youTableName;
--解锁某个分区
unlock table youTableName partition(dt='2014-04-01');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 附录: 常用DDL
Hive常用DDL:
--查看所有分区
show partitions table_name;
--查看特定过滤的分区
show partitions table_name partition(dt=20180528);
--修改分区:
alter table page_view ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808'
PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';
--删除分区
alter table table_name drop partition(dt=20180420);
--添加分区
alter table table_name add partition (dt=20180420) location '分区数据位置';
--分区改名
alter table table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
--移动分区:Move partition from table_name_1 to table_name_2
alter table table_name_2 EXCHANGE PARTITION (partition_spec) WITH TABLE table_name_1;
--修复分区:如果直接将数据复制到hadoop目录下,hive的metastore中不会更新。所以需要更新(修复)分区
MSCK REPAIR TABLE table_name;
--实例:Hive复制分区表结构及数据
--1. 复制表结构
create table new_table_name like old_table_name;
--2. 拷贝原表数据文件到新表目录下
dfs -cp /apps/hive/warehouse/app.db/fact_incar_orders/\* /apps/hive/warehouse/app.db/fact_incar_orders_test/;
--3. 修复新表分区
MSCK REPAIR TABLE fact_incar_orders_test;
--增加hive表字段
alter table dws.dws_staff_orders add columns(create_user_name string COMMENT '创建工单人名称');
--在CLI中显示数据库名
set hive.cli.print.current.db=true;
--在CLI中显示SELECT字段名
set hive.cli.print.header=true;
--设置使用tez执行
set hive.execution.engine=tez;
--修改表名
alter table employee RENAME TO emp;
--修改列名称:数据类型一定要加
alter table dws.dws_incar_user CHANGE create_cancel_minutes order_avg_create_cancel_minutes int;
--导入本地文件到hive表中
load data local inpath '/home/hadoop/dws_fyd_order_bills.txt' into table dws.dws_fyd_order_bills;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54