
 Hive的介绍及安装
Hive的介绍及安装
# Hive介绍
官方文档 (opens new window)说Hive是一个数据仓库基础工具,在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
注意
Hive底层是将基础SQL语句转换为MapReduce程序进行运行,所以可以理解为Hive是MapReduce的一个客户端工具
Hive 不是
- 一个关系数据库
- 一个设计用于联机事务处理(OLTP)
- 实时查询和行级更新的语言
Hive 特点
- 它存储架构在一个数据库中并处理数据到HDFS。
- 它是专为OLAP设计。
- 它提供SQL类型语言查询叫HiveQL或HQL。
- 它是熟知,快速,可扩展和可扩展的。
# Hive架构
下图介绍了Hive的架构
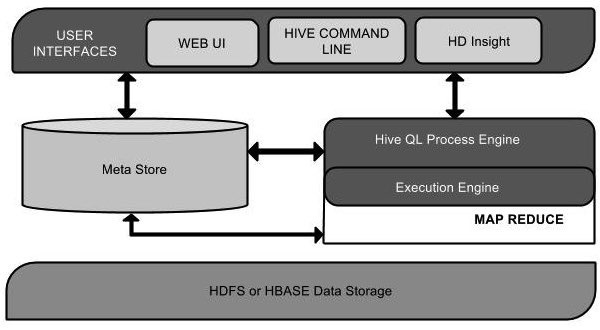
User Interfaces:Hive为用户提供了3个接口,WebUI,命令行接口,HD洞察(在Windows服务器)
Meta Store:元数据存储,Hive的运行需要元数据,Hive其实就是将HDFS上的文件映射成一张数据库表,该数据库表中存储了元数据信息。
Hive QL Process Engine:Hive QL的处理引擎,类似于SQL的查询,替代了传统使用Java编写MapReduce的方式。
Execution Engine:执行引擎,HiveQL和MapReduce的结果需要Hive执行引擎来处理
HDFS or HBASE:Hive可以读取HDFS上的数据或者HBASE上的数据
# Hive工作原理
下图介绍了Hive连接Hadoop的工作原理
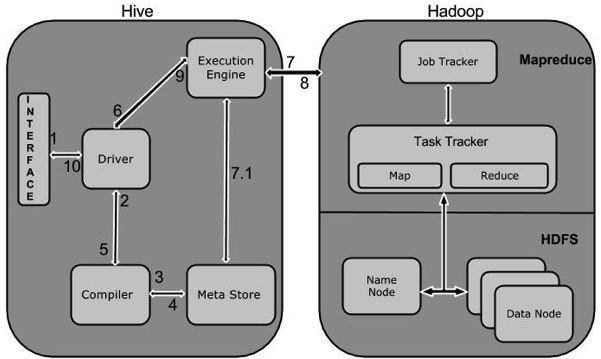
- Hive的接口(如命令行或者WebUI)发出查询驱动程序。
- 根据驱动程序的帮助,查询编译器。用于分析检查SQL语法和查询计划或查询的要求。
- 编译将SQL编译完后,读取元数据信息。
- 元数据存储库响应请求,返回该SQL的元数据信息。
- 编译器再次检查要求,并重新发送计划给驱动程序。到此,查询解析和编译就完成了。
- 驱动程序发送执行计划到执行引擎。
- 执行作业的过程其实就是执行MapReduce程序,执行引擎会将作业发送给Job Tracker,Job Tracker会分配作业到相应的Task Tracker。Task Tracker负责执行MapReduce工作。
- 执行引擎会接收数据节点处理的结果。
- 执行引擎将处理的结果发给驱动程序。
- 驱动程序再将结果响应给用户接口。
# Hive的安装
Hive的安装有3种方式
- 嵌入方式:将Hive的元数据存储在derby数据库中,该方式只能创建一个连接。
- 本地模式:将Hive的元数据存储在另外的数据库中
- 远程模式:Hive的元数据信息保存在另外服务器上,数据库不和hive在同一台机器上。
Hive的安装很简单,直接下载解压。直接就可以启动了。
注意
注意:Hive依赖于Hadoop和JDK,最好也要把zookeeper给安装好。
# Hive的下载
hive-1.2.2下载地址 (opens new window)
下载apache-hive-1.2.2-bin.tar.gz
解压apache-hive-1.2.2-bin.tar.gz 文件
tar -zxvf apache-hive-1.2.2-bin.tar.gz
# 切换Hive的元数据存储derby为Mysql
由于Hive运行时需要存储元数据信息,而Hive默认使用Apache derby数据库
Apache Derby是一个完全用 java 编写的数据库,Derby是一个Open source的产品。
Apache Derby非常小巧,核心部分derby.jar只有2M,既可以做为单独的数据库服务器使用,也可以内嵌在应用程序中使用。
Derby的特点
- Derby定位是小型数据库, 特别是嵌入式. 支持的数据库小于50GB, 对于小型网站, 事务不复杂的应用, 使用它的还是很不错的. 另外大型桌面应用也可以用它来保存配置和其他数据, 可以做到与文件格式无关, 因为都是访问数据库.
- 功能: Derby支持标准SQL92, SQL1999, SQL2003, 支持临时表, 索引, 触发器, 视图, 存储过程, 外键, 约束, 并行, 事务, 加密与安全等. 只要有JDK(>=1.3), 就可以运行Derby.
- 安全性:Derby的安全性也做得很到位, 包括用户鉴权和加密解密.
- 性能:Derby的性能也是不错的.在插入100万条记录时, CPU的占用率一直低于40%, 平均每插一条记录耗时小于0.3毫秒. 这对于满足桌面应用程序是绰绰有余的. 但是比Oracle、MySql等专业数据库性能要低。
由于Derby的性能低,所以这里我们把hive的元数据存储在mysql上
# 切换derby为MySQL
编辑/usr/local/hadoop/hive-1.2.2/conf/hive-default.xml.template文件,这里为了方便。我们备份一个hive-default.xml文件出来
cp hive-default.xml.template hive-site.xml
然后在hive-site.xml中修改如下配置项。
也可以直接新建hive-site.xml文件,拷贝如下内容即可。
hive-site.xml内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mini1:3306/hive_metadata?useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
<property>
<name>hive.exec.parallel.thread.number</name>
<value>8</value>
<description>How many jobs at most can be executed in parallel</description>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 拷贝MySQL驱动包
将mysql-connector-java-5.1.14.jar拷贝到Hive安装的lib目录/usr/local/hadoop/hive-1.2.2/lib下。
# 初始化hive元数据
在hive的bin目录下执行如下代码,进行初始化metadata
[root@mini1 bin]# ./schematool -dbType mysql -initSchema
# Hive的启动
直接执行Hive的bin目录下的hive可执行文件即可。
[root@mini1 bin]# ./hive
Logging initialized using configuration in jar:file:/usr/local/hadoop/hive-1.2.2/lib/hive-common-1.2.2.jar!/hive-log4j.properties
Java HotSpot(TM) Client VM warning: You have loaded library /usr/local/hadoop/hadoop-2.7.4/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
hive>
2
3
4
5
启动完成可以看到hive>的命令提示符,表示启动成功。