
 Sqoop1.99.7将mysql数据导入到hdfs
Sqoop1.99.7将mysql数据导入到hdfs
# 准备
本示例将实现从MySQL数据库中将数据导入到HDFS中
参考文档: http://sqoop.apache.org/docs/1.99.7/user/Sqoop5MinutesDemo.html (opens new window) http://blog.csdn.net/m_signals/article/details/53190965 (opens new window) http://blog.csdn.net/lazythinker/article/details/52064165 (opens new window) http://blog.sina.com.cn/s/blog_61d8d9640102whof.html (opens new window)
mysql数据库信息: test库中user表中的记录(共1条)
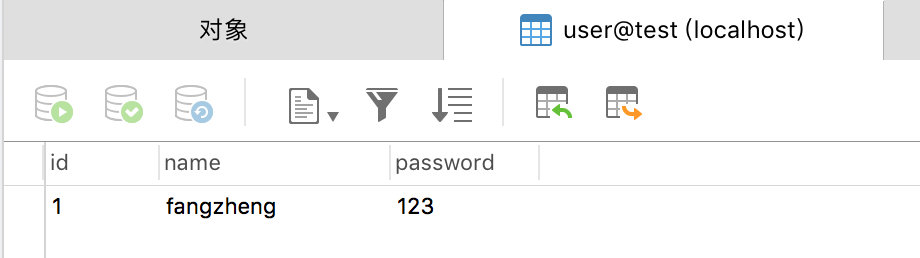
HDFS数据情况 
创建了一个/root/test的空目录
实现目标: 本示例需要实现将上方MySQL数据库中的数据导入到HDFS中
# 开始
启动Hadoop,启动sqoop,命令行进入sqoop
## 设置交互的命令行打印更多信息,打印的异常信息更多
set option --name verbose --value true
## 连接sqoop,其中hadoop1是需要连接的sqoop的主机名
set server --host hadoop1 --port 12000 --webapp sqoop
## 查看连接
show version --all
2
3
4
5
6
# 创建link
如果需要使用sqoop进行导入导出操作,需要先创建连接, 使用show conncetor命令可以查看sqoop支持的连接器, 而sqoop中默认提供了如下几种连接。
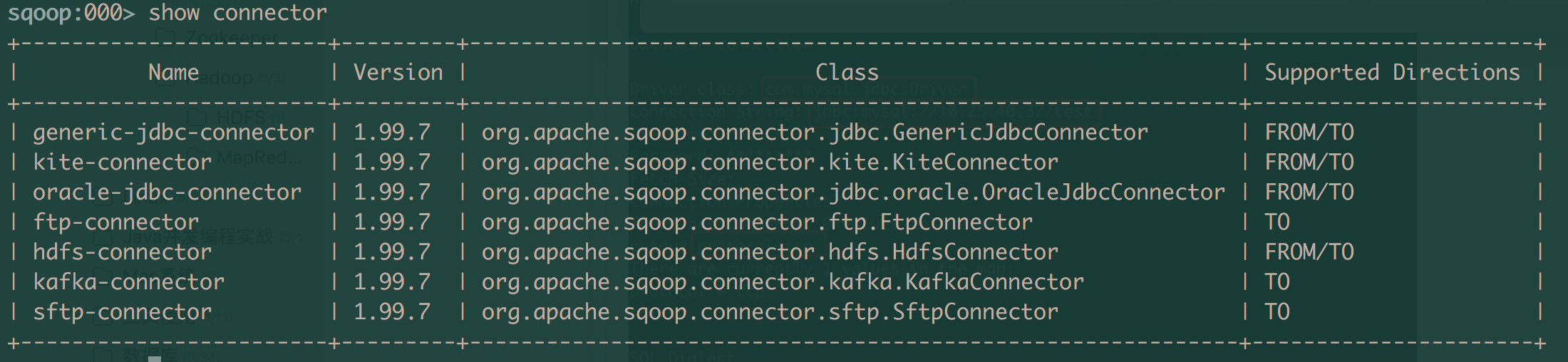
# 创建mysql-link
本例实现mysql-->hdfs的数据导入操作,所以需要创建一个mysql的link和hdfs的link。
注意:在创建mysql-link的时候需要将mysql的jar包放入到$SQOOP2_HOME/server/lib/extra-lib目录中
首先创建mysql-link,过程如下
sqoop:000> create link -connector generic-jdbc-connector
Creating link for connector with name generic-jdbc-connector
Please fill following values to create new link object
Name: mysql-link
Database connection
Driver class: com.mysql.jdbc.Driver
Connection String: jdbc:mysql://10.25.40.37/test
Username: root
Password: *********
Fetch Size:
Connection Properties:
There are currently 0 values in the map:
entry## protocol=tcp
There are currently 1 values in the map:
protocol = tcp
entry##
SQL Dialect
Identifier enclose:
New link was successfully created with validation status OK and name mysql-link
sqoop:000>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
以上输入项说明,下图中红色的表示需要输入的内容。
注意Identifier enclose项需要输入一个空格,然后回车

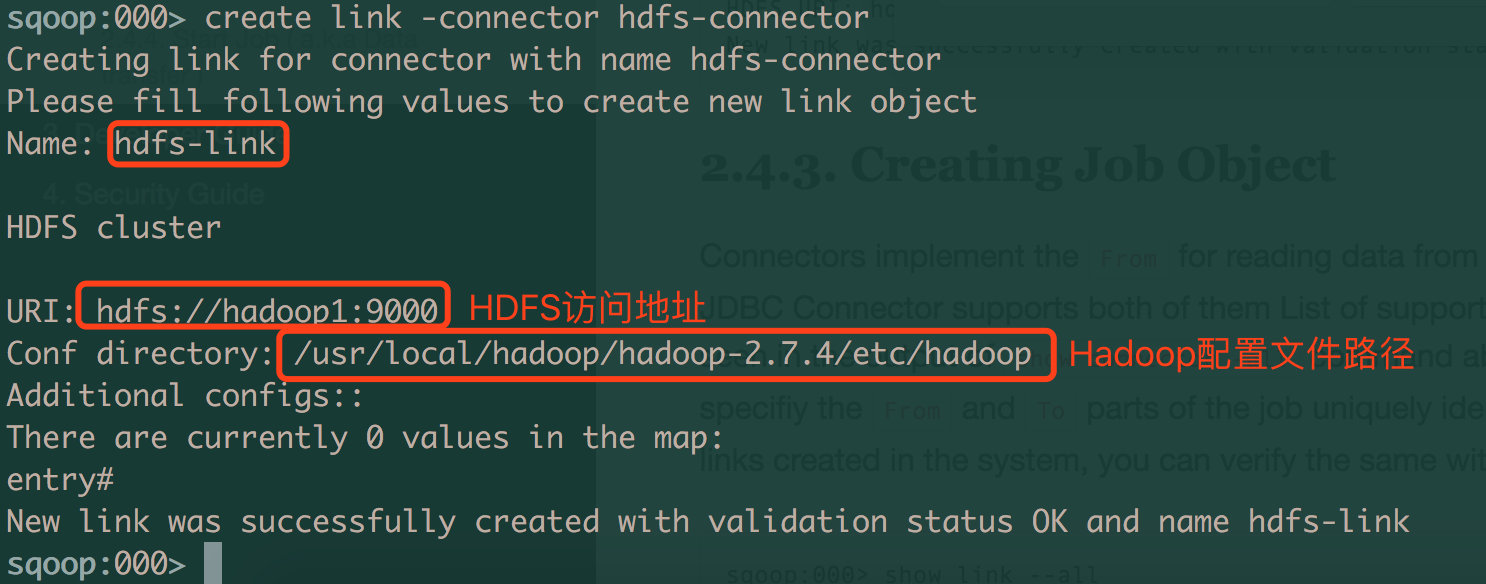
# 创建hdfs-link
创建HDFS的link的配置就比较简单,配置HDFS访问地址和hadoop配置文件目录路径即可
sqoop:000> create link -connector hdfs-connector
Creating link for connector with name hdfs-connector
Please fill following values to create new link object
Name: hdfs-link
HDFS cluster
URI: hdfs://hadoop1:9000
Conf directory: /usr/local/hadoop/hadoop-2.7.4/etc/hadoop
Additional configs::
There are currently 0 values in the map:
entry##
New link was successfully created with validation status OK and name hdfs-link
sqoop:000>
2
3
4
5
6
7
8
9
10
11
12
13
14
# 创建job
创建job时,配置项较多。 命令:
## create job -f formLinkName -t toLinkName
create job -f mysql-link -t hdfs-link
2
注意下面中文部分
sqoop:000> create job -f mysql-link -t hdfs-link
Creating job for links with from name mysql-link and to name hdfs-link
Please fill following values to create new job object
Name: test1(job名称)
Database source
Schema name: test(数据库的schema名称)
Table name: user(数据库表名)
SQL statement:
Column names:
There are currently 0 values in the list:
element##
Partition column:
Partition column nullable:
Boundary query:
Incremental read
Check column:
Last value:
Target configuration
Override null value:
Null value:
File format:
0 : TEXT_FILE
1 : SEQUENCE_FILE
2 : PARQUET_FILE
Choose: 0(选择文本文件)
Compression codec:
0 : NONE
1 : DEFAULT
2 : DEFLATE
3 : GZIP
4 : BZIP2
5 : LZO
6 : LZ4
7 : SNAPPY
8 : CUSTOM
Choose: 0(选择NONE)
Custom codec:
Output directory: /root/test(这里输入HDFS文件的目录,需要是空目录)
Append mode:
Throttling resources
Extractors: 2(这里是参考官网填的2)
Loaders: 2(这里是参考官网填的2)
Classpath configuration
Extra mapper jars:
There are currently 0 values in the list:
element##
New job was successfully created with validation status OK and name test1
sqoop:000>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 启动job
命令
## start job -name jobName
start job -name test1
2
# 验证是否导入成功
查看HDFS中的/root/test/目录中的数据,共出现了2个文件

查看文件内容
 可以看到2ea38d69-e9e4-4364-adfc-67d88f5c8153.txt文件中已经存在了导入的数据,而8962bce1-08e7-4ebc-939e-4839d05eb145.txt是个空文件。
可以看到2ea38d69-e9e4-4364-adfc-67d88f5c8153.txt文件中已经存在了导入的数据,而8962bce1-08e7-4ebc-939e-4839d05eb145.txt是个空文件。
# 期间遇到的问题及解决方案
以下问题均是创建完link和job后,开始启动job时报的错。
# 1. Host '10.25.40.37' is not allowed to connect to this MySQL server
Host '10.25.40.37' is not allowed to connect to this MySQL server

错误原因: 这问题表示主机10.25.40.37没有授权外部访问其MySQL
解决方案:
将连接的MySQL主机中的授权信息改了
- 直接改mysql库中user表root的那条记录,将其值改为%(表示任何主机都可访问)

- 使用授权命令,授权指定的主机可访问该数据库(推荐:更安全)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'username'@'%' IDENTIFIED BY 'password' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
2
详细操作步骤可自行百度。
# 2. User: root is not allowed to impersonate root
User: root is not allowed to impersonate root

错误原因: 该错误是因为在安装sqoop时,在hadoop的core-site.xml配置文件中配置的用户权限错误 在之前的sqoop安装文章里,按照官网的配置如下。其中hadoop.proxyuser.sqoop2.hosts中的sqoop2是用户的意思,同理hadoop.proxyuser.sqoop2.groups中的sqoop2是用户组的意思。
<property>
<name>hadoop.proxyuser.sqoop2.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sqoop2.groups</name>
<value>*</value>
</property>
2
3
4
5
6
7
8
解决方案:
将sqoop2改为root即可,改完后如下:(PS:这里的解决方案感觉还是有问题不完美,没有深入了解)
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
2
3
4
5
6
7
8
# 3. GENERIC_HDFS_CONNECTOR_0007:Invalid input/output directory - Unexpected exception
GENERIC_HDFS_CONNECTOR_0007:Invalid input/output directory - Unexpected exception
输入输出目录有问题,检查HDFS中是否存在相应目录即可
# 4. There are 0 datanode(s) running and no node(s) are excluded in this operation
There are 0 datanode(s) running and no node(s) are excluded in this operation

错误原因: 启动job的时候报的错,这应该是datanode节点数据的问题
解决方案:
- 配置dfs.datanode.data.dir和core-site.xml里面的hadoop.tmp.dir一致 hdfs-site.xml里面的 dfs.datanode.data.dir /tmp/hdfs_tmp 与core-site.xml里面的 hadoop.tmp.dir /tmp/hdfs_tmp 两个配置应该是指向同一个目录地址,而且必须是一个已经存在的linux目录(不存在目录的话,在启动hadoop时,必须手动创建,否则put文件到hdfs系统时就会报错),今天报这个错就是因为两个配置没有指向同一个目录地址,且两个地址还不存在对应的目录
参考: http://blog.sina.com.cn/s/blog_61d8d9640102whof.html (opens new window)
- 删除dfs.namenode.data.dir中的current文件夹中的内容,格式化namenode,重新启动hadoop 参考: http://blog.csdn.net/qiruiduni/article/details/50280943 (opens new window)
最后我使用了1解决方案后问题解决了,但是不知道以后会不会有其他问题。
# 5. Call From hadoop1/192.168.56.110 to 0.0.0.0:10020 failed on connection exception
Call From hadoop1/192.168.56.110 to 0.0.0.0:10020 failed on connection exception

问题原因:
报错信息提示,在访问端口 100020的时候出错,这表示DataNode 需要访问 MapReduce JobHistory Server,而默认值是: 0.0.0.0:10020 。
解决方案:
找到{HADOOP_HOME}/etc/hadoop/mapred-site.xml配置文件 ,增加如下配置:
<property>
<name>mapreduce.jobhistory.address</name>
<!-- 配置实际的主机名和端口-->
<value>{namenode}:10020</value>
</property>
2
3
4
5
这里我的主机名是hadoop1,所以配置的值是hadoop1:10020

参考: http://blog.csdn.net/lazythinker/article/details/52064165 (opens new window)
# 6. GENERIC_HDFS_CONNECTOR_0007:Invalid input/output directory - Output directory is not empty
GENERIC_HDFS_CONNECTOR_0007:Invalid input/output directory - Output directory is not empty

错误原因: 输入或者输出目录不是空目录,本示例的错误原因是之前启动job后,在HDFS里已经导入过一些数据进去。没删除,所以报这个错。
解决方案: 删除该目录下的内容即可 清空上方创建job时指定的output目录(/root/test)中内容即可。